





























 Assistant
Assistant
Unstructured Data Guide
Table of contents.
Navigate guide
The Enterprise Guide to Unstructured Data in the Age of Agentic AI
Here is a stat that keeps getting more dramatic every year: more than 90% of all enterprise data is now unstructured. According to the Komprise 2026 State of Unstructured Data Management report, 74% of enterprises are storing more than 5 petabytes of unstructured data — a 57% increase over 2024 — and 40% now store more than 10 petabytes. Global data volume is expected to reach 221 zettabytes in 2026, with the vast majority unstructured and growing at three times the rate of structured data.
Unstructured data is everywhere. It is exploding in volume. And in the era of Agentic AI, it is no longer just a storage problem — it is the foundation upon which intelligent, autonomous enterprise systems are built. Without access to this data, AI agents cannot reason, retrieve, or act on the knowledge your organization has spent decades accumulating.
This guide covers what unstructured data is, where it lives, how to analyze it, and — critically — how it connects to the rise of Agentic AI and enterprise AI search.
What Is Unstructured Data?
Unstructured data is information that does not conform to a predefined data model or schema. Unlike rows and columns in a database, unstructured data comes in formats like text documents, emails, PDFs, images, audio, video, chat logs, and social media posts. It lacks the rigid organization that makes structured data easy to query with traditional tools like SQL or pivot tables.
Despite being harder to manage, unstructured data often contains the richest insights an enterprise possesses. Customer sentiment buried in support tickets, intellectual property hidden in engineering reports, and regulatory risk lurking in email threads — these are signals that structured data alone cannot capture.
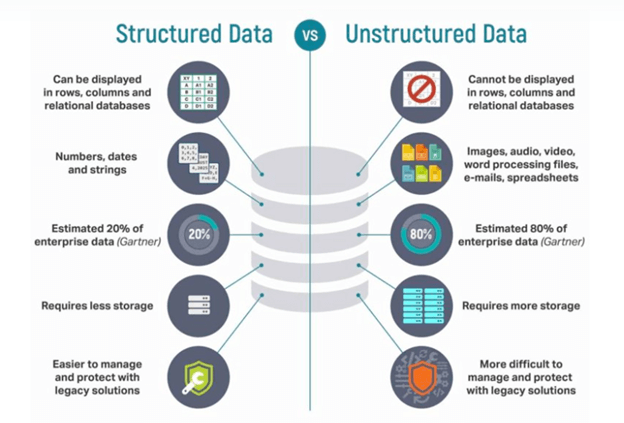
Structured vs. Unstructured Data
- Structured data fits neatly into the fields of a relational database management system (RDBMS) like Oracle or Microsoft SQL Server. Think names, addresses, transaction amounts, timestamps. It is organized, queryable, and represents roughly 10–20% of an organization’s total data.
- Unstructured data is everything else — and it accounts for the other 80–90%. Word documents, presentations, contracts, emails, videos, social media content, and sensor feeds all fall into this category. Because it cannot be organized into rows and columns, traditional analytics tools like regression analysis and BI dashboards often cannot process it directly.
- Semi-structured data occupies the space in between. Formats like JSON, XML, HTML, and email headers contain some organizational markers but do not fit cleanly into a relational schema.
The critical takeaway: organizations that only analyze structured data are working with a fraction of the picture. To become truly data-driven — and to power AI systems that can reason across your full knowledge base — you need a strategy for unstructured data.
Read more: Structured vs. Unstructured Data: The Ultimate Guide
Examples of Structured and Unstructured Data
- Common examples of structured data include: Lead and sales records in CRM systems (e.g., Salesforce, HubSpot), procurement and inventory data in ERP systems (e.g., SAP), supply chain planning and logistics data, GPS and location data from mobile devices, customer ratings and demographic information, and financial transaction logs.
- Common examples of unstructured data include: Emails and internal communications, Microsoft Office documents (Word, PowerPoint, Excel), PDF reports, contracts, and technical manuals, social media posts, comments, and sentiment data, audio recordings, video files, and images, chat and instant messaging logs (Slack, Teams, etc.), call center transcripts, IoT sensor data, satellite imagery, and scientific research data.
In addition to human-generated unstructured data, enterprises now deal with massive volumes of machine-generated unstructured data from IoT devices, industrial sensors, autonomous systems, and AI model outputs — all of which need to be ingested, understood, and acted upon.
Why Is Unstructured Data Important in 2026?
Unstructured data has always been important, but three converging forces have made it mission-critical.
1. It is the fuel for generative AI and Agentic AI. Large language models, retrieval-augmented generation (RAG) pipelines, and enterprise AI agents all depend on access to unstructured content. An AI assistant that can only reference structured database records will deliver shallow, incomplete answers. An AI agent grounded in your full corpus of documents, emails, technical manuals, and research reports can reason with the depth and context your workforce needs. As MIT Technology Review recently noted, the real barrier to scaling Agentic AI is not model quality — it is the data foundation underneath.
2. Data volumes have reached a tipping point. Enterprises are not just storing more data — they are storing exponentially more. The Komprise survey found that 85% of IT leaders project increased storage spend in 2026, and data classification for AI readiness is now their top strategic priority. Organizations that cannot see, classify, and govern their unstructured data are flying blind.
3. Compliance and security demand it. Regulations like GDPR, CCPA, and HIPAA require organizations to know what data they hold, where it is, and who can access it. Personally identifiable information (PII) and intellectual property can easily be embedded in unstructured documents — email attachments, scanned contracts, internal memos. Without the ability to discover and classify this content, organizations face significant legal and financial exposure.
Where Does Unstructured Data Live?
One of the defining challenges of unstructured data is its sprawl. It lives across dozens of systems, in hundreds of formats, often without centralized visibility. Here are some of the most common locations:
Cloud collaboration platforms (Microsoft 365, Google Workspace, Slack, Teams), on-premises file servers and network drives, document management systems (SharePoint, Documentum, OpenText), email servers (Exchange, Gmail), CRM and ERP notes and attachments, engineering and PLM systems, social media platforms, call center and chatbot conversation logs, IoT platforms and industrial sensor repositories, and cloud storage (Box, OneDrive, AWS S3, Azure Blob).
In addition to knowing where your data lives, the challenge in 2026 is making it accessible to AI. Enterprise AI agents need to traverse these silos in real time, retrieve relevant content, and synthesize answers — all while respecting security permissions. This requires a robust connector infrastructure and an intelligent indexing layer that can handle 350+ document formats and 200+ enterprise data sources.
Learn how Sinequa connects to your data: Sinequa Connectors
How Do You Analyze Unstructured Data?
Analyzing unstructured data requires specialized tools that go far beyond traditional BI and database queries. Here is how modern enterprises approach it:
Enterprise AI Search. A platform like Sinequa’s Enterprise AI Search deploys intelligent crawlers that ingest content from across your entire data estate — SharePoint, email, file servers, cloud apps, databases, and more. The platform parses and indexes content from hundreds of document formats, building a unified, searchable knowledge layer.
Natural Language Processing (NLP). Advanced NLP reads documents the way a human would, extracting named entities (people, organizations, dates, monetary values), identifying relationships, detecting sentiment, and understanding context across 20+ languages. This is essential for turning raw text into structured, queryable intelligence.
Retrieval-Augmented Generation (RAG). Advanced RAG combines the precision of enterprise search with the generative capabilities of large language models. Rather than relying on an LLM’s training data alone, RAG retrieves relevant documents from your own knowledge base and feeds them to the model at inference time — producing answers that are grounded, accurate, and traceable.
AI-Powered Data Classification. Automated classification uses machine learning to tag unstructured content by sensitivity (PII, IP, confidential), topic, department, or any custom taxonomy — at scale and in real time. This is foundational for both governance and AI readiness.
Read more: How to Harness Unstructured Data and Gain Insights
What Role Does Unstructured Data Play in Agentic AI?
Agentic AI refers to AI systems that can autonomously plan, reason, and execute multi-step tasks on behalf of users. Unlike simple chatbots that respond to a single prompt, AI agents can break down complex goals, retrieve information from multiple sources, call tools, take actions, and iterate — all without constant human supervision.
Unstructured data is the knowledge base that makes Agentic AI useful in the enterprise. Here is why:
AI agents need grounding in real-world context. An AI agent tasked with analyzing a compliance risk needs access to regulatory filings, internal audit reports, email correspondence, and policy documents. These are unstructured. Without them, the agent can only hallucinate or provide generic responses.
Multi-step reasoning requires multi-source retrieval. When a maintenance engineer asks an AI agent to diagnose an equipment failure, the agent may need to cross-reference service manuals, historical maintenance logs, parts databases, and sensor data. Agentic AI orchestration coordinates this retrieval across structured and unstructured sources simultaneously.
Agents must respect enterprise security. Unlike consumer AI tools, enterprise AI agents must enforce document-level access controls. Sinequa’s security and trust layer ensures that AI agents can only retrieve and surface content that the requesting user is authorized to see — a non-negotiable requirement for regulated industries.
The quality of unstructured data determines AI ROI. As organizations move from AI pilots to production-scale deployments, the bottleneck is rarely the model — it is the data. Organizations that invest in cleaning, classifying, and connecting their unstructured data will see dramatically better results from their AI agents. Those that do not will stall at the pilot stage.
Explore Sinequa’s Agentic AI capabilities: Enterprise Agentic AI Platform
What Are the Challenges of Unstructured Data?
Despite its value, unstructured data remains one of the hardest categories of enterprise information to manage. Here are the primary challenges organizations face:
Volume and growth. Unstructured data is growing at 55–65% annually according to Gartner. Legacy storage and management approaches designed for a few terabytes cannot keep pace with petabyte-scale estates.
Siloed and fragmented. Data is scattered across cloud apps, on-premises systems, email servers, and collaboration tools. Without a unified search and retrieval layer, employees spend hours searching for information they know exists but cannot find.
Classification and governance gaps. The Komprise 2026 survey found that classifying and tagging unstructured data is the number-one challenge in preparing data for AI. Without classification, organizations cannot enforce data retention policies, comply with privacy regulations, or curate training data for AI models.
AI readiness. Only a small fraction of enterprise unstructured data has been filtered, classified, or prepared for use with AI systems. The gap between “data stored” and “data usable by AI” is enormous — and closing it is now the top priority for IT leaders.
Security and compliance risk. Sensitive data — PII, trade secrets, regulated information — can easily be embedded in unstructured documents without anyone knowing. This creates exposure under regulations like GDPR, CCPA, HIPAA, and industry-specific mandates.
What Value Can Unstructured Data Bring to Your Business?
When properly analyzed, classified, and connected to AI systems, unstructured data can transform how an enterprise operates.
Faster, better decisions. Employees who can search across all enterprise content — not just structured databases — make more informed decisions. Engineers find technical precedents faster. Compliance teams identify risks earlier. Sales teams access competitive intelligence in real time.
Higher AI accuracy and ROI. AI agents and assistants grounded in a comprehensive, well-governed knowledge base deliver more accurate, relevant, and trustworthy answers. This translates directly to user adoption and measurable productivity gains.
Reduced redundancy and waste. A unified search platform eliminates duplicate work by surfacing existing documents, research, and assets before employees recreate them from scratch. It also connects individuals and teams working on similar problems.
Accelerated innovation. When researchers and engineers can search across patents, publications, internal reports, and competitor filings in a single interface, they spot opportunities and avoid dead ends far more quickly. Industries like life sciences, manufacturing, and aerospace and defense rely on this capability daily.
Stronger compliance posture. Automated data discovery and classification reduce audit preparation time, improve breach response, and demonstrate regulatory diligence to auditors and regulators.
Competitive advantage in the Agentic AI era. Organizations that have connected, classified, and secured their unstructured data are the ones that will scale AI from pilot to production. Those that have not will continue to struggle with hallucinating models, low user trust, and stalled ROI.
See how enterprises are achieving this: Customer Stories
Ready to unlock the value of your unstructured data?
Sinequa’s Enterprise Agentic AI Platform connects to 200+ data sources, processes 350+ document formats, and powers trusted AI agents, assistants, and search — all with enterprise-grade security. Book a Demo
See Enterprise Agentic AI in action
Book a DemoShare



