





























 Assistant
Assistant
The Art of Content Analysis

The past decade has seen the democratization of data analysis . Armed with Tableau or Power BI tools, data analysts can quickly digest vast amounts of data to uncover useful insights and inform important decisions.
However, this only works when the data is adequately organized, curated, centralized, structured, and formatted. Unfortunately, a big part of the data of large organizations is stored in documents of varying types and formats scattered across multiple repositories and teams.
In most organizations, information is created and stored to be interpreted by people rather than machines. Humans are great at reading documents, remembering who knows what, and deducing where to look for a particular piece of information within a loosely organized and heterogeneous environment. In contrast, computers prefer predictable structures and formats, as you would find in a database.
What is Content analysis
Content analysis is the art of deciphering data that was never meant to be processed by a computer. A combination of technology and methodology makes it possible to extract useful information from chaos. It can give a global picture of an entire organization when applied at scale.
Ideally, content analysis could reconcile the dichotomy between “human friendly” and “computer friendly” data. Imagine an algorithm reading all your emails and being able to answer any questions about them, like an oracle. “Why did I choose this supplier back in 2014?” “Which contract under my management expires this month?” … Now imagine this oracle with ALL your company’s emails, documents, and messaging tools.
Technology is not yet at that level, but the gap is closing rapidly. It is likely that content analysis will become so good in the following decade that it will transform organizations and vastly increase their productivity.
Content Analysis for contracts
Let’s take the example of contract analysis: Contracts are typically stored as PDF documents, with little metadata and varying formatting. A company might have thousands of contracts and agreements with other companies scattered across multiple information systems.
If this data were structured , it would be trivial to answer such questions as “list the suppliers with whom our lease contracts expire by April 24th”. Legal officers and lawyers often deal with such queries by reading the contracts and manually extracting that information into a database or spreadsheet. Of course, this process is slow, painful, and error-prone.
But content analysis can help here. There is no universal “one-size-fits-all” approach but a set of technologies that can be combined to process these contracts, extract useful information, and answer complex questions:
- First, contracts can be systematically retrieved from their original locations using connectors, web crawlers, and web services.
- Then, content must be extracted from the PDF documents: Raw text, titles, bookmarks, tables, and even images can also be processed with Optical Character Recognition (OCR) to extract the text.
- Natural Language Processing (NLP) algorithms can perform several tasks, like recognizing the language and meaning of individual words and noun groups. NLP can also recognize and normalize relevant chunks of information, like people’s names, companies, dates, amounts of money, etc.
- Machine Learning (ML) has made significant leaps forward in recent years. One of the most common use cases is text classification, which can be very useful for categorizing a type of contract or even a specific type of clause within a contract. But new Deep Learning models can go much further by encoding the meaning of a chunk of text, which unlocks several applications.
- Intelligent Search can leverage the NLP and ML analysis to retrieve key passages from contracts. Crucially, Search is quickly moving from “finding the right document” to “finding the right answer (within the right document)”.
- Finally, Data Analysis comes as the last layer on top of the above technologies. Tools like Tableau or Power BI can ingest the structured data generated with NLP and ML techniques and bring the data to life in insightful dashboards.
The example dashboard below was generated by Sinequa from a corpus of PDF contracts, using all the technologies listed above.
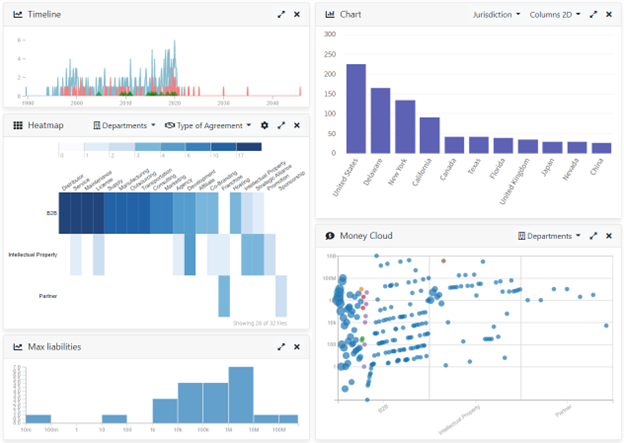
Content Analysis is more art than science
There are many ways of extracting information from documents. Content analysis can seem more art than science because no single approach applies to all problems. Depending on the type of information we look for, we must choose the right tool at our disposal.
In recent years, there has been a tendency to apply Machine Learning to every problem. Large language models are doing wonders in all Natural Language Processing (NLP) problems. However, the effort required to train large language models to solve particular issues can be prohibitive. Often, the optimal solution is to use a combination of methods.
For example, it is possible to train a language model to extract the name of companies found in documents. However, most of the time, we aren’t interested in ANY company name. Some companies may be competitors, some might be suppliers, and others, customers.
Of course, you could train a language model to recognize which companies are suppliers and which are customers. But the effort required would be massive compared to directly matching those names to the words found in documents.
Machine learning could also be trained to detect dates written out entirely, like “April 24, 2022”. However, we generally want this format normalized, typically as something more easily exploitable programmatically, like “2022-04-24”. Because of this normalization problem, traditional NLP techniques may be better suited than Machine Learning. In the example below, Sinequa’s NLP has extracted a date and normalized it as the machine-readable “1999-09-30”:

On the other hand, Machine Learning is great at capturing the general meaning or intent of a sentence or short paragraph. Going back to our Contract Analysis use case, a Machine Learning model can easily find that this sentence tells us when the contract expires, even though it does not explicitly contain a date:
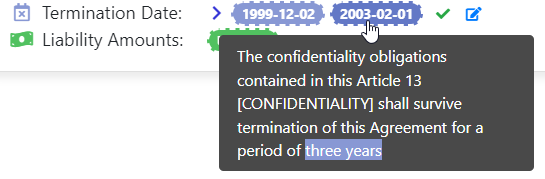
Getting the same result with traditional NLP is difficult because there are so many ways you could formulate such a sentence. However, traditional NLP is great at extracting “three years” from this sentence, which can then be added to the initial date of the contract. This date can be extracted with a combination of Machine Learning and NLP.
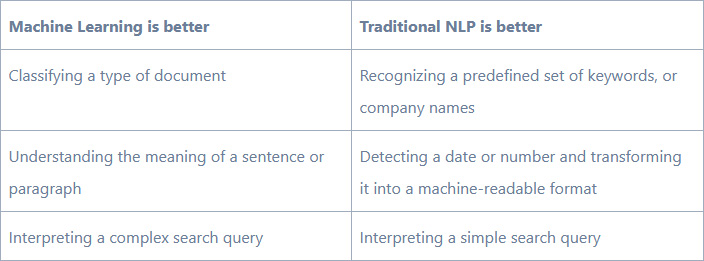
Therefore, what matters is to have a well-stocked toolbox to select the right tool for a given job. The table below provides some examples:
The big picture
Content Analysis is always a part of a more extensive process. Content evolves, and any human- or computer-generated analysis can include mistakes or become outdated. As the saying goes, “Garbage in, garbage out”! The more important the results, the more critical it is to consider the entire lifecycle of the information:
- What happens when the source information changes? Does that invalidate past results?
- How can users verify and validate the analysis? All ML and NLP algorithms make mistakes: so it is critical to end users to be able to double check results and validate or invalidate them when needed.
- What happens when a mistake is detected? When using traditional NLP, bugs are relatively easy to understand and fix. But when using Machine Learning, a bug means that you should probably retrain your model!
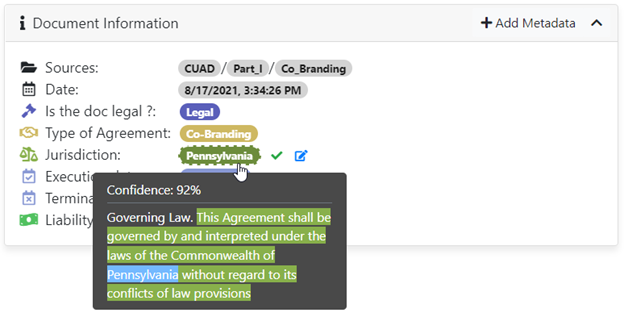
For instance, with Sinequa users can see the results of predictions in context. Users can verify why a prediction was made at a glance and validate or invalidate that prediction:
Conclusion
Deploying Content Analysis solutions at scale in a complex environment can be challenging because it is never about having one good tool or algorithm. It invariably involves multiple tools and a complete process that must encompass data collection, OCR, NLP, ML, and user-facing applications that render the results in context and let users validate or modify them.
Platforms like Sinequa offer an infrastructure in which all these bricks are already integrated. That’s not to say that no work is needed: It is still necessary to configure and assemble these bricks into a system that works and is maintainable. This level of packaging and integration facilitates quick projects with small teams.
Share






